GroupByKey vs ReduceByKey
GroupByKey and ReduceByKey => Both are transformations
val wordcountUsingReduceByKey =
inputRDD.reduceByKey(_+_).collect
GroupByKey
|
ReduceByKey
|
|
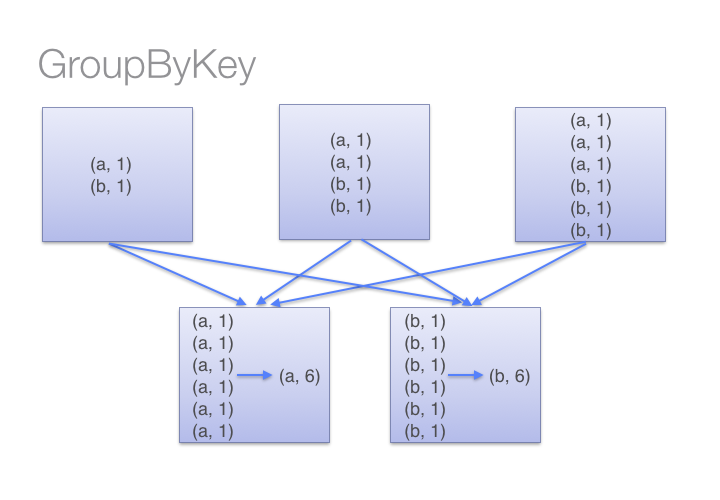
Groups the dataset based on the key
|
Grouping + Aggregation
|
|
Shuffling
|
More shuffling
|
Less shuffling
|
Combiner
|
No Combiner
|
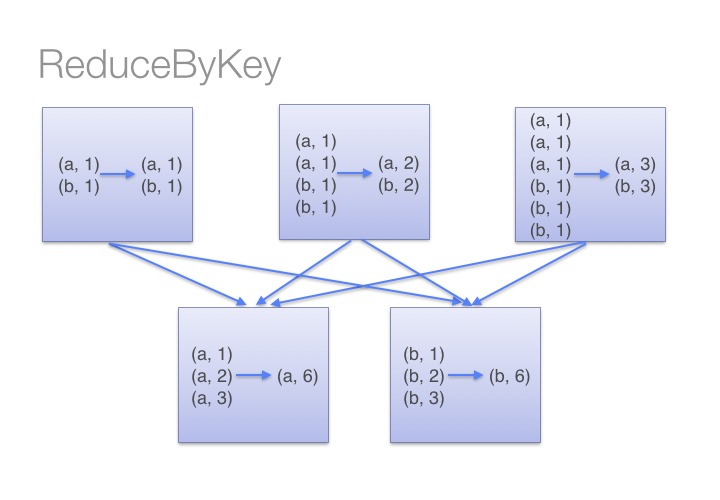
Aggregates the data before shuffling
|
Which one is better?
|
All the key,value pairs are shuffled around. This is a lot
of unnecessary data transfer on the network.
|
Works better on larger dataset, because spark knows that
it can combine the output with a common key on each partition before
shuffling the data.
The function that’s
passed to reduceByKey will be called again to reduce all the values from each
partition to produce the final result.
Only one output for each key at each partition to send
over network.
|
Partitioner method
|
Will be called on each and every key.
|
|
Disk spill
|
If there is more data to be shuffled on to a single
executor machine than can fit in memory.
|
|
Out or memory exeption can occur
|
Single key has more key, value pairs than can fit in
memory an out of memory exception can occur.
However, it flushes the out the data to disk one at a
time.
|
|
Performance impact
|
When disk spill happens, performance will be severely
impacted
|
|
Preferred functions to be used
|
combineByKey –
can be used when combining the results, but the return type will differ
foldByKey – merges the values for each key using
an associative function
|
Example
word count:
val
input = Array(“a”,”a”,”b”,”b”,”c”,”c”,”c”)
val
inputRDD = sc.parallelize(input).map(element => (element,1))
val
wordcountUsingGroupByKey = inputRDD.groupByKey.map(words => (words._1,
words._2.sum)).collect

Comments
Post a Comment